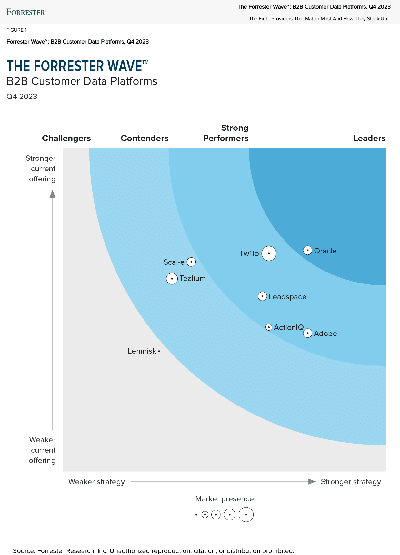
Find, create and prioritize closeable business. Again and again.

How it works
Bring the graph, studio and your own first party data altogether and connect them to your CRM to build a powerful system to uncover your TAM, ICP and much more to accurately target closeable demand.
The Graph.
Enrich your data. Search and create segments for your campaigns.
The Graph is fueled by 30+ of the best third party B2B data sources around. It understands account hierarchies and tens of thousands of buying signals to validate, accurately match leads to accounts and score not just at the company level but at the buying center level. Bring in your first party data to complete the picture.
B2B Sources
Companies
Contacts
Mobile Phones
Sell better.
Buying center hierarchies and CRM tool integration means better routing, better territory planning and better sales engagement.
Learn MoreSupercharge your CRM with enriched and scored data.
Buying center hierarchies and CRM tool integration means better routing, better territory planning and better sales engagement.
Learn MoreThe Studio.
A single place to see, shape and tailor your go-to-market strategy.
The Studio helps your sales and marketing teams find, create and prioritize closeable business. Discover and analyze your Total Addressable Market and Ideal Buyer Profile. Create fit models. Search the Buyer Graph. Segment and score. Activate segments in sales and marketing tools and ad platforms.
The B2B Graph and Filter Rich Company Data.
Enrich, Unify and Target Companies, Personas and Contacts.
Social, Ads, Sales and Marketing Automation Programs.
Total Addressable Market, Ideal Buyer Profile, Data Health and More.
Get your data house in order. Fast.
Enrich accounts and personas with expert third party data sources. Unify data sources and segments with your first party data to add business context.
Learn More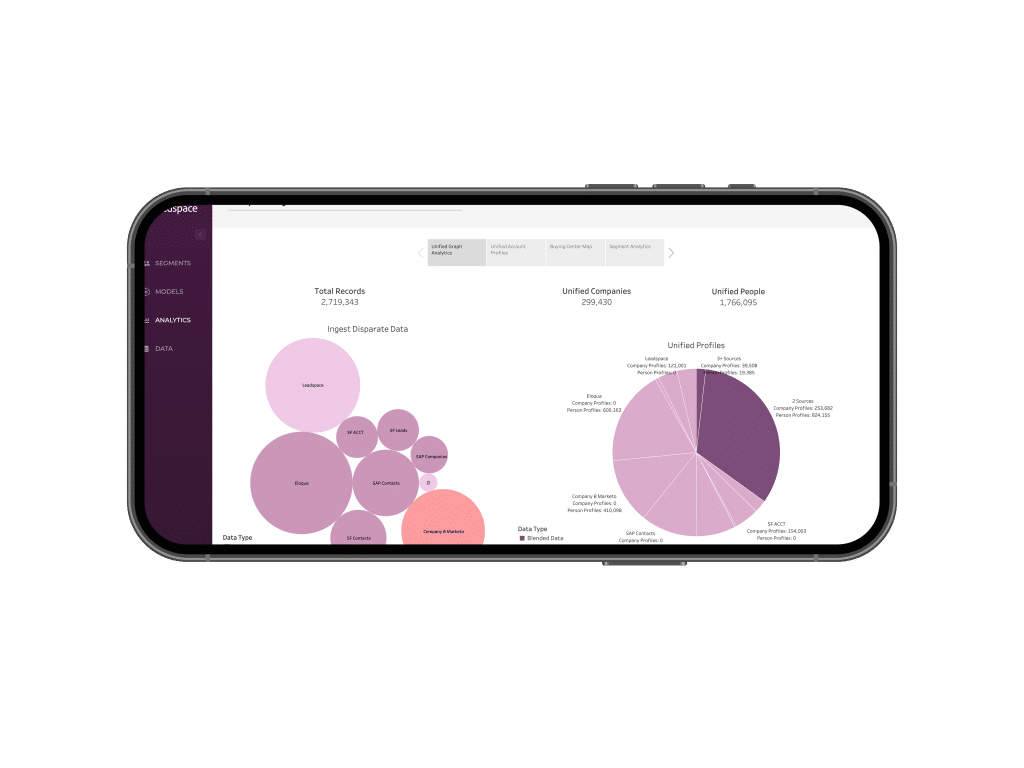
Enrich Accounts and Personas with expert 3rd Party data sources. Unify data sources and segments with your 1st party data to add business context.
Learn More
Eric Lewis
VP Demand Generation
“With Leadspace, we have built the next generation of demand generation technology and process. Leadspace gives us a huge competitive advantage, now and for the future.”